KNN - Understanding K Nearest Neighbor Algorithm in Python

K Nearest Neighbors is a very simple and intuitive supervised learning algorithm.
A supervised learning algorithm is one in which you already know the result you want to find.
It works like this you give your model a dataset having data and results, using the data your
model creates a decision boundary to predict the desired result.
It is a really intuitive and simple algorithm and it can be used both as classifier and as regressor.
I will not give you a standardized definition of classification and regressor as it might confuse
you let’s understand with an example: Given a dataset of features of cat and dog your job is to
tell by examining the features that given animal is cat or dog this is a classification problem
while you are given a dataset of houses having various features and price of houses on
examining the data you have to predict the price of a house given to you as query this is a
regression problem here you are not classifying you are predicting a value.
Now first we will see and implement kNN and then we will see how it can be used both as a
classifier and a regressor.
kNN Algorithm
Your algo would receive a query point in the dataset and you have to give results on this
query point.Calculate Euclidean distance of query points from the nearest k points(k nearest
neighbors).Store these distances in a list.
Sort the list.
Take the majority vote and predict results.
So, it is pretty simple we first get a query for example on a 2-D feature set query can be [2, 3].
We take the nearest k points and calculate the distance of each point from the query point.

Take a look at the picture above we have the black dot as query and we have k=3 so we
calculate the distance of 3 nearest points and store distance in a list then we will sort the list
and as we can see more points belong to the dataset at the top so the query belongs to the
data member at the top.
Let’s now see the code which would give you a much better idea about the algorithm.
First, we will import important libraries we have imported sklearn to make dummy data,
matplotlib.pyplot for making plots and NumPy library which a very famous library for
carrying out mathematical computations.

Now, we will create dummy data we are creating data with 100 samples having two
features.

Let’s first see how is our data by taking a look at its dimensions and making a plot of it.
X contains 100 samples of two featured data, we will put feature 1(indexed as 0) in
variable x_axis and feature 2(indexed1) in y_axis and plot it out in a scatter plot using
function “plt.satter(x_axis, y_axis)”, we have also plotted a query point as you can see in
the pic below.

We have created a dictionary while I will be talking about after we have completed the
kNN algorithm. We have also created a distance function to calculate Euclidean Distance
and return it.

Finally, we have arrived at the implementation of the kNN algorithm so let’s see what we
have done in the code below.We have defined a kNN function in which we will pass X, y, x_query(our query point)
, and k which is set as default at 5.We have taken variable m which is the number of training examples using
statement — m = X.shape[0].We have created an empty list named distances.
Now, we will iterate over samples and calculate the distance of these points from
query points and we will append this distance as well as the label of the point in the
dataset in the distances list.After iterating over the whole dataset we will sort the list using the sorted function
you can use any other method if you want.We will split the first k rows of the
sorted distances list.Converting a list to numpy array will help us a lot to perform mathematical
computations a lot easier. As we have stored both distance and label we have
created a new variable label and store the first column and all rows.We now find the unique labels and number of times these labels occur and store
them in two variables ‘uniq_label’ and ‘counts’ and we can predict by finding the
unique label having maximum occurrence using argmax() function.

Now we can run a query on our model and see the prediction, note that we have returned
the dictionary name corresponding to the result by using dic[int(pred)].

kNN As A Classifier
We can use kNN as a classifier and the example above is also a classification problem and I
don’t think there is nay more need to explain kNN as a classifier, I will just show how we can
use kNN as a classifier to classify images of the famous Mnist Dataset but I won’t be
explaining it only code will be shown here, for a hint it will group all the numbers in different
cluster calculate distance of query point from all other points take k nearest and then predict
the result.
Using kNN for Mnist Handwritten Dataset Classification
kNN As A Regressor
kNN can also be used as a regressor, formally regressor is a statistical method to predict the
value of one dependent variable i.e output y by examining a series of other independent
variables called features in machine learning.
We will use kNN to solve the Boston House prediction problem.
Boston House Price Prediction
Importing libraries — Matplotlib for plotting data, sklearn for model, dataset, and
train_test_split.

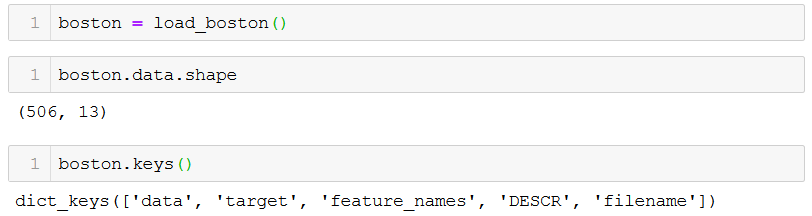
Loading boston dataset and we will see the shape of our data and keys of data to get an
idea about our data.
Splitting train and test set.

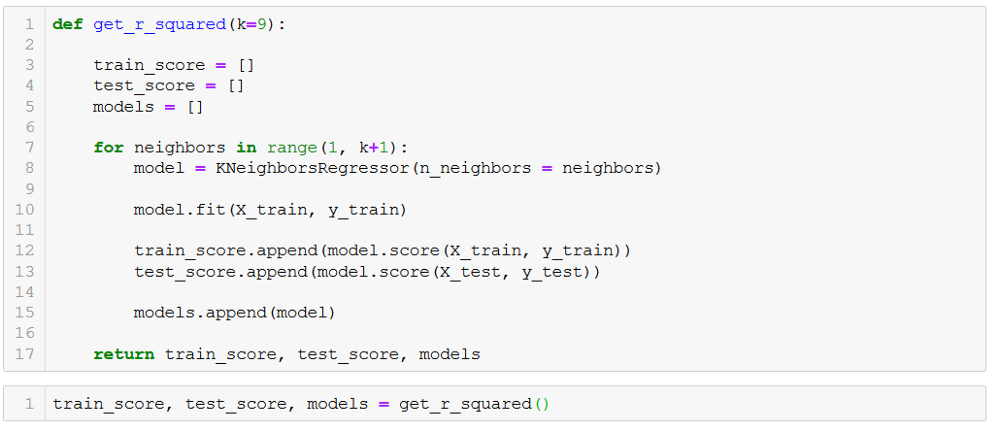
Here we are using the sklearn to implement knn I choose it to show you the usage of
sklearn as till now we have just coded knn all the way from scratch. It is pretty simple
with sklearn we are predicting for different values of k to see variations and it has two
steps first passing parameters in the model, second fitting it for train data, to examine
the model we calculate r squared error (also called r2 error) using the inbuilt score
method of sklearn and at the end, we are returning the test_score, training_score and
the list of models for different values of k.We are calling our function and saving the values in the respective variables.
Here are the predictions by model for varying k.

Examining performance for k=6.

Let’s plot a graph for both train and test data. R-squared error is pretty low which shows
that kNN doesn’t work well as a regressor.

What should be the value of K?
Choosing the value of k is crucial as it will determine the accuracy of your algorithm and it can
change the performance of your algorithm. So, the big question arises is what should be the
value of k? Let’s see…
The value of k should be large as it is better to consider more neighbors but it should not
be at the cost of speed that should be always kept in mind.Value of k should not be even as it might be the case that for a query the distances
belonging to different datasets might be equal for example, suppose there are 2
categories and value of k=6, now the query point is nearest to the equal number of
points belonging to both categories and now model can’t distinguish and give you
result.
You can take sqrt(n) as a good approximation of k but it is advisable to try a few values of k
and choose the most optimized value.
Advantages
KNN is pretty intuitive and simple: K-NN algorithm is very simple to understand and
equally easy to implement.K-NN has no assumptions: kNN is a non-parametric algorithm and hence it has no
assumptions unlike other algorithms like linear regression.No Training Step: K-NN does not explicitly build any model, it simply gives results on
the new data entry, based on learning from historical data. New data entry would be
tagged with the majority class in the nearest neighbor.It constantly evolves: k-NN is a memory-based approach. The classifier immediately
adapts as we collect new training data. It allows the algorithm to respond quickly to
changes in the input during real-time use.Very easy to implement for the multi-class problem: Most of the classifier algorithms
are easy to implement for binary problems and need effort to implement for multi-class
whereas KNN adjusts to multi-class without any extra efforts.Can be used both for Classification and Regression: One of the biggest advantages
of KNN is that KNN can be used both for classification and regression problems.One Hyper Parameter: Choosing the right value of hyperparameter can be a very painful
experience which is not the case with kNN as it has only one hyperparameter.Variety of distance criteria to choose from: KNN algorithm gives users the flexibility to
choose distance while building KNN model. There are various methods to calculate
distance:
Euclidean Distance
Hamming Distance
Manhattan Distance
Minkowski Distance
Disadvantages
Slow algorithm: K-NN might be very easy to implement but as the dataset grows,
efficiency or speed of algorithm declines very fast.Dimensionality: KNN works well with a small number of input variables but as the
numbers of variables grow K-NN algorithm struggles to predict the output of the new
data point.KNN needs homogeneous features: If you decide to build k-NN using a common
distance, like Euclidean or Manhattan distances, it is completely necessary that features
have the same scale, since a given distance in one feature must mean the same for the
second feature.Optimal value of neighbors: One of the biggest issues with KNN is to choose the
optimal value of hyperparameter k to be considered while classifying the new data entry.Imbalanced data causes problems: kNN doesn’t perform well on imbalanced data.
If we consider two classes, A and B, and the majority of the training data is labeled as A,
then the model will ultimately give a lot of preference to A. This might result in getting the
less common class B wrongly classified.Outlier sensitivity: KNN algorithm is very sensitive to outliers as it simply chose the
neighbors based on distance criteria.
Comments
Post a Comment